Abstract
The Four-data center replication described in this paper proposes a solution that addresses customer requirements for continuous uptime and data currency while operating from the Disaster Recovery site, after a regional disaster or for political reasons. This solution also provides a way to address logical data corruption when occurs at the primary site, for certain period of time, which otherwise gets propagated to other DR sites rendering the redundant copies of the data useless.
There is lack of four-way replication solutions in the market currently and the proposed solution uniquely positions HPs Disaster Recovery capabilities and enhances HPs Go-to-Market in this domain. The benefits are tremendous in that HP can gain competitive advantage in providing better storage availability and win more storage deals.
Problem statement
A successful disaster recovery solution should resonate with customer’s business mission and the reliability required for business continuity. Today’s banking industry is facing a challenge of continuous uptime for their critical services and zero data loss that helps reduce competitive exposure. Now-a-days customers tend to run their business from Disaster Recovery site (DR) for a defined period due to political, economic, operation reasons and terrorist threats to primary site. In such cases customers expect a DR solution for the DR which warrants Zero Recovery Point Objective (RPO) and our solution of 4DC (Data Center) addresses it.
The 4DC solution provides multi-target replication to protect from hardware failures even if the application services are running from the Far Site and sustain the data currency in case any logical or physical block corruptions in database/applications subject to the re-sync interval between Data volume and the recovery volume.
Our solution
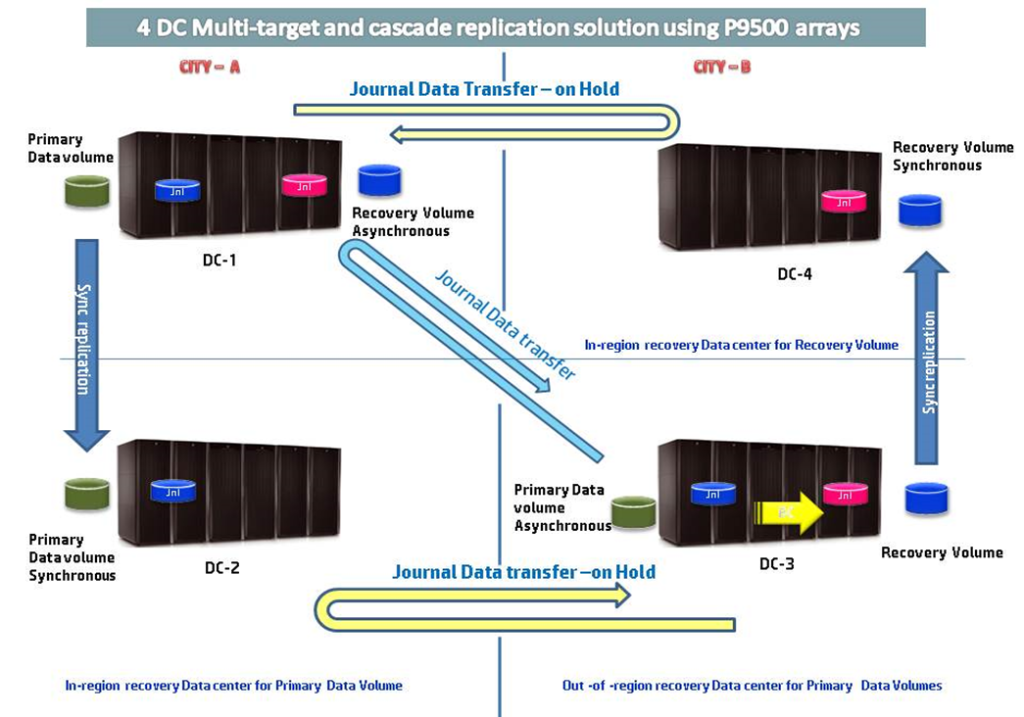
The proposed architecture uses four HP P9500 Disk Arrays in Four datacenters across two cities in different regions defined by geographical, political, economic and operation reasons of the customer.
The first Two Datacenters are located close to one another, and the other two are also located close to one another but outside the region defined by Production Site. In one scenario, the primary (DC1) and secondary (DC2) data centers within same region sites synchronously replicate data between themselves, while the primary asynchronously replicates data to the remote or tertiary out-of-region data center (DC3) forming a usual 3Three datacenter architecture.
At the remote data center (DC-3) a HP StorageWorks Business Copy (BC) is taken at defined interval, per the customer application requirements, that provides a means to block propagation of logical data corruption, if it ever occurs at the primary datacenter. Thus the BC at the remote site remains isolated from the source and can eventually be used as a fall back in case of a logical corruption at the primary site (DC-1).
The BC secondary volume (SVOL) at DC-3 is in a synchronous replication relationship with its Near Site (DC-4) and the original primary volume replicated back to the Primary site (DC-1) asynchronously, forming an inverted 3 DC approach. This replicated volume back at the Primary Site (DC-1) ensures that Primary Site has a copy of the data that lags at a maximum of the interval defined at the Far Site (DC-3), which is available for a quick roll back in the event of a logical data corruption in the primary site.
If disaster struck the Primary Site (DC-1), activity could continue at the Near Site (DC-2). In the event of a regional disaster, operations can continue from the Far Site (DC-3), using the business copy SVOLs after sync with the PVOLs at this site, which still has an active synchronous replication relationship with its Near Site (DC-4), which ensuring continuous availability even after a regional disaster. In the event of the Far Site (DC-3) failure while operating from DR the Near Site (DC-4) for DR location can be used for continuing operations.
With the existing replication techniques a complex implementation solution as explained in the below diagram (Figure1) is evolved to cater the customer requirement such as Near Site (DC-4) for Far Site (DC-3) while running Services from DR and also provides a data protection from logical corruption for certain period of time.
Evidence the solution works
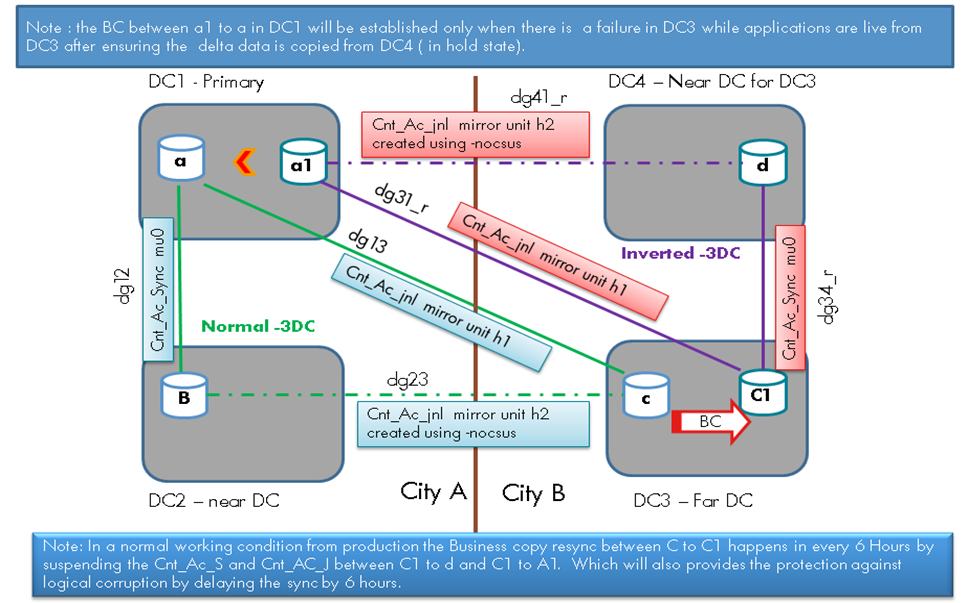
The picture below (Figure 2) explains the behavior and the sequence of replication. This has been simulated and tested in the HP STSD labs (unofficial testing).
The volume “C1” at DC-3 is replicated to volume “d” at DC-4 over Continuous Access (CA) Sync and to volume “a1” at DC-1 using CA Journals. Once in every 6hrs the CA relationships between the volumes “C1” and “a1” will be suspended to allow for a BC re-sync between the volumes “c” and “C1” at DC-3.
The CA sync relationship will then be re-established which allows the data copies in the inverted-3DC isolated and lags by a maximum of 6hrs from the Normal – 3DC. This process is fully automated and tested using scripts.
Competitive approaches
Currently only 3DC solutions are available in market. Competitors are trying to evolve 4DC solution, but still not available in their solution portfolio.
Current status
This solution has been tested in a Proof-of-Concept (POC) environment and demonstrated to few customers.
Next steps
Once this solution gets certified by HP Storage Works Division (SWD), it can be sold to Mission critical customers.
References
HP Storage Works 3 Data Center Replication
http://xpnow.rose.hp.com/support/downloads/documentation/white_papers/700-600-500-3dc_wp-1104xx.pdf
HITACHI the book portfolio guide (Page 29)
http://www.nxtbook.com/nxtbooks/hitachi/thebook2012/index.php